AI Feedback Loops
As image generation models evolve and improve, I find it fascinating to see how stories evolve from a single image and prompt. As images are progressively transformed you can observe preferences in race, culture and politics, discover guardrails and see artifacts and distortions that emerge.
I developed a CLI tool that works with OpenRouter as a way to research and compare different image models and to identify their biases and limitations. It creates AI-generated animations by iteratively transforming images - give it a starting image and a "mode" (a preset prompt), and it runs multiple passes of image generation, passing each output as the next input. The result is a sequence of progressively transformed frames, compiled into a video or GIF.
 _prompt: "show what happens moments later in this scene", model: Gemini 3/Nano Banana Pro _
_prompt: "show what happens moments later in this scene", model: Gemini 3/Nano Banana Pro _
The tool does quite a lot: it tracks metadata like costs, processing time and tokens. It handles model selection, image sizing and aspect ration, saving images, gif and videos, and interruption/continuation of running jobs. It also comes with a gallery viewer which helps to inspect results and filter by model or prompt.
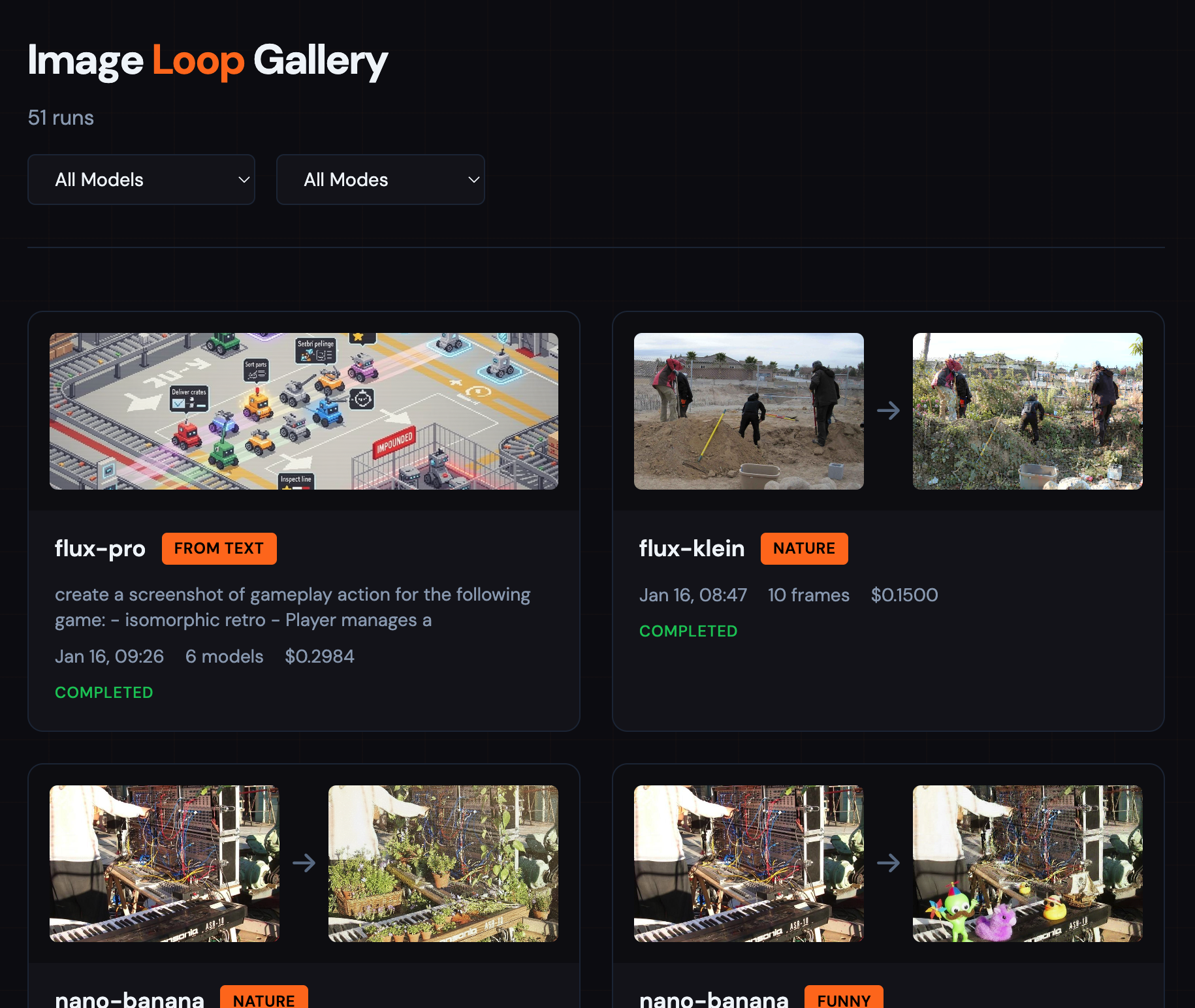 The web-based gallery browser.
The web-based gallery browser.
There's a lot of different prompts included, some of them proved quite interesting. Some examples:
| Mode | Prompt |
|---|---|
| wes-anderson | Adjust this image so it look a bit more like a Wes Anderson movie. |
| corrections | Find something wrong with this image and fix it. |
| crowded | Subtly add more people or objects to make this scene feel more populated or busy. |
| politic-right | how would this image look if it was just a bit more 'politically right' or conservative |
| politic-left | how would this image look if it was just a bit more 'politically left' or liberal |
| realistic | make this image more realistic, fixing any fake or unrealistic elements |
| next | show what happens moments later in this scene |
| opposite | consider the deeper meaning of this image and show the opposite of what is shown |
| redacted | replace any redacted black square with the likely original content that was obscured, then find a new area of the image to redact and cover it with a black square. |
| drone | the camera is attached to a flying drone filming a video flyby, show the next frame of this footage. |
| Another prompt that proved interesting: time lapse: |
 Starting with just a single photo, a fictional time lapse sequence emerges.
Starting with just a single photo, a fictional time lapse sequence emerges.
Research is ongoing, but some curious patterns emerged: models like Riverflow turn all subjects into asians after around 10 generations. Models from Google and OpenAI will refuse to generate images that might be slightly politically charged, or show potential accident or harm - other models just don't care. Some image models struggle with movement, instead relying on photoshop-like replacements, while others like Nano Banana and Flux.ai will imagine entire 3D positioning from a single photo.
The source code and docs are available at somebox/ai-feedback-loops - it's fairly easy to set up and use and is backed with tests. I developed it in Cursor with Claude Opus 4.5 in Dec 2025.
